
Our research group's interests are in statistical signal processing, machine learning and optimization. Within these areas we work on a variety of fundamental problems (adaptive representations, classification, clustering, computational signal processing, and machine learning) and in a variety of application domains (fMRI analysis, image processing, video analysis and search).
Recent research projects have supported by grants from the National Institute of Mental Health, the National Science Foundation, INTEL, a Google Fellowship in Neuroscience, Princeton's University's Charlotte Elizabeth Procter honorific fellowship, and the Insley Blair Pyne Fund.
Example Research Projects
Analysis of Functional Magnetic Resonance Imaging Data
This work has been funded by grants from the National Institute of Mental Health (5R01MH075706-02), the National Science Foundation (NSF-1129764 and NSF-1129855), a grant from INTEL Labs, a Google Fellowship in Neuroscience, and the Insley Blair Pyne Fund
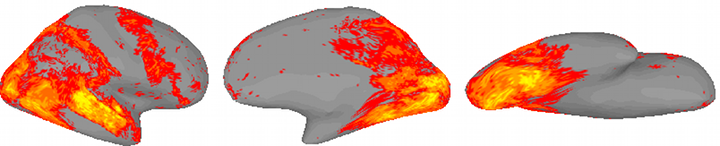
In collaboration with neuroscience colleagues, we are developing algorithms for functionally aligning the fMRI data of multiple subjects measured during a movie viewing. We have developed various methods, using distinct alignment metrics, for accomplishing this goal:
-
Time series cortical functional alignment: This method is based on the correlation of corresponding cortical time series. The method and associated results were published in 2009 in Cerebral Cortex and the software (MATLAB code) is available on-line.
-
Functional connectivity alignment: This is based on aligning intra-subject cortical functional connectivity. The fundamental aspects of the method are outlined in our NIPS 2009 paper and a more detailed analysis is given in our 2013 paper in NeuroImage.
-
Time series hyperalignment: This based on aligning time series trajectories via subject specific orthogonal transforms. The method is detailed in our 2011 paper (Haxby et. al.) in Neuron. An extension to Regularized time series hyperalignment is described in our IEEE SSP Workshop paper in 2012; and an extension to Kernel times series hyperalignment is described in our NIPS 2012 paper.
-
Shared response model: This is latent variable model for learning subject specific functional response patterns and a reduced dimension shared feature time responses. See our NIPS paper in 2015. This has a kernel extension and a searchlight based extension.
-
Convolutional autoencoder: This work uses a convolutional autoencoder for learning a shared low dimensional representation of functional response patterns that preserves spatial locality in the brain.
-
BrainIAK: We continue to contribute to the open-sourced Brain Imaging Analysis Kit (BrainIAK). BrainIAK currently has highly optimized implementations of our Shared Response Models (see above). More extensions will be added in the near future.

Dictionary Based Classification and Structured Dictionaries
Learning a sparse representation of new data in terms of a dictionary is a state of the art method for modeling data. But when the dictionary is large and the data dimension is high, it can be a computationally challenging problem. We are exploring three aspects of the problem. First, we are developing new screening tests that quickly identify dictionary atoms that are guaranteed to have zero weights. This work is described in several of our recent papers:
-
Sphere tests are described in our 2009 NIPS paper (Xiang et al)
-
Dome test is described in our 2012 ICASSP paper (Xiang, Ramadge)
-
Two hyperplane tests are introduced in our 2013 ICASSP papers.
-
Screening Tests for Lasso Problems This a journal length survey article giving a comprehensive view of screening tests for the lasso problem.
Second, we have been exploring the application of these ideas to large scale real world datasets including music genre classification and large document collections. See for example:
-
Our paper at CISS 2012, Music Genre Classification Using Multiscale Scattering and Sparse Representations, describes a dictionary based method using scattering that achieves very high accuracy. Out subsequent work has refined this to yield even better performance.
-
Our paper on Screening Tests for Lasso Problems includes an analysis of an example database of 300,000 documents each described by a vector of 100,000 features.
Third, we are developing a hierarchical framework that uses incremental random projections to learn a structured dictionary for sparse representation in small stages. Initial experiment results show that our framework can learn informative hierarchical sparse representations in a more time efficient manner. See our paper at NIPS 2011 (Xiang et al).
Spatially Aware Learning
When applying off-the-shelf machine learning algorithms to data with spatial dimensions (images, geo-spatial data, fMRI, etc) a central question arises: how to incorporate prior information on the spatial characteristics of the data? For example, if we feed a boosting or SVM algorithm with individual image voxels as features, the voxel spatial information is ignored. Indeed, if we randomly shuffled the voxels, the algorithm would not notice any difference. Yet in many cases the spatial arrangement of the voxels together with prior information about expected spatial characteristics of the data may be very helpful. We are particularly interested in the situation when the trained classifier is used to identify relevant spatial regions. To make this more concrete, consider the problem of training a classifier to distinguish two different brain states based on fMRI responses. Successful classification suggests that the voxels used are important in discriminating between the two classes. Hence we could use a successful classifier to learn a set of discriminative voxels. We expect that these voxels will be spatially compact and clustered. How can this prior knowledge be incorporated into the training of the classifier? To learn more, please read our paper (Xiang et al) in NIPS 2009.
Statistical Image Processing
A variety of image and signal processing problems can be formulated as minimizing the sum ||f-g|| + R(f). The first term encodes the desire that f be near a given signal g and the second term is a regularization penalty on the complexity of f. So we want a good but simple approximation f to the given signal g. An challenge in formulating the term R(f) is ensuring that sharp edges and meaningful high frequency features in natural signals and images are not unduly penalized. Many traditional regularization methods fail to meet this challenge because the regularizer is agnostic to the edge structure of f. A modern solution selects R(f) to be the L1 norm of the coordinates of f in a wavelet basis. Despite the huge success and popularity of this approach, there is interest in improvements in the following two areas: (a) The use of nonlinear wavelets; (b) A more flexible image decomposition structure. This project is developing new signal representations and studying how these representations can compactly represent signals of interest. One application is edge aware signal denoising. To learn more please read our papers at ICASSP 2010 (Xiang & Ramadge) and ICIP 2010 (Xiang and Ramadge). The software for the algorithms in these papers is available on-line.